mysql插入性能
https://blog.csdn.net/yangxiao_hui/article/details/103262704
https://blog.csdn.net/weixin_41725792/article/details/110186011
将多次插入改为一次插入能明显的提高效率,降低时延
但是mysql插入还是慢的,开发的时候,323个字段,13000+条记录,需要9s多的耗时(只有一个主键索引的情况下),所以如果遇到大批量,大表的插入,还是需要异步处理。
创建表
emoji表情是用四个字节表示的,而utf是1-3个字节编码的,会导致emoji表情因为字符集问题无法插入到db中,需要修改为utf8mb4才可以。
例如在使用django执行原生sql时,会报这种字符集错误:
django.db.utils.OperationalError: (1366, "Incorrect string value: '\xF0\x9F\x98\x81</...' for..
create table table_name (col_name1 type,[col_name2 type])
DEFAULT CHARSET utf8 COLLATE utf8_unicode_ci;
CREATE TABLE tbl_name (column_list)
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]]
ALTER TABLE tbl_name
[[DEFAULT] CHARACTER SET charset_name]
[COLLATE collation_name]
mysql执行语句的长度上限
由变量max_allowed_packet控制
show variables like '%max_allowed_packet%';
展示的数字是字节数,可以一般是1M或者4M
mysql 查看表字段数量
SELECT count(1) from information_schema.COLUMNS WHERE table_schema='linkhealthy' and table_name='tb_sign_file';
mysql 创建表后的一些字段含义
create table user_op_info(id int(11) NOT NULL AUTO_INCREMENT, user_name varchar(32) DEFAULT '',timestamp int(15) unsigned NOT NULL DEFAULT '0' COMMENT '用户请求时间戳', interface_name varchar(50) NOT NULL DEFAULT '' COMMENT '用户请求的接口名',request_input text NOT NULL COMMENT '用户请求接口的json请求包',PRIMARY KEY(id)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1
使用innodb引擎,自增列从1开始自增,默认的字符集编码为latin1.
mysql复制表结构
CREATE TABLE IF NOT EXISTS new_table (LIKE old_table);
like方法能一模一样的将一个表的结果复制生成一个新表,包括复制表的备注、索引、主键外键、存储引擎等。
复制表的数据到另一张表
insert into new_table select * from old_table;
insert into new_table(field1,field2) select field1,field2 from old_table;
insert into new_table(field1,field2) select field1,field2 from old_table where id = 5;
mysql权限
https://www.cnblogs.com/richardzhu/p/3318595.html
除了增删改查以外,还有文件权限,文件权限决定了用户是否可以导出数据库的数据:
select * from table into outfile 'output.txt';
mysql查询表的创建时间
SELECT table_name,create_time
FROM information_schema.TABLES WHERE table_name = 'table_name';
mysql插入当前时间戳
insert into black(remark,create_time) values('黑名单',unix_timestamp());
转换时间戳为格式化时间
select from_unixtime(timestamp_field) from table;
查询事务相关的信息以及锁的状态
https://cloud.tencent.com/developer/article/1401617
SELECT * FROM information_schema.INNODB_TRX; 查看正在运行的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS; 查看正在锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS; 查看等待锁的事务
show full processlist; 查看所有连接本mysql的客户端信息
show open tables where in_use > 0; 查看目前被占用表锁的表信息:
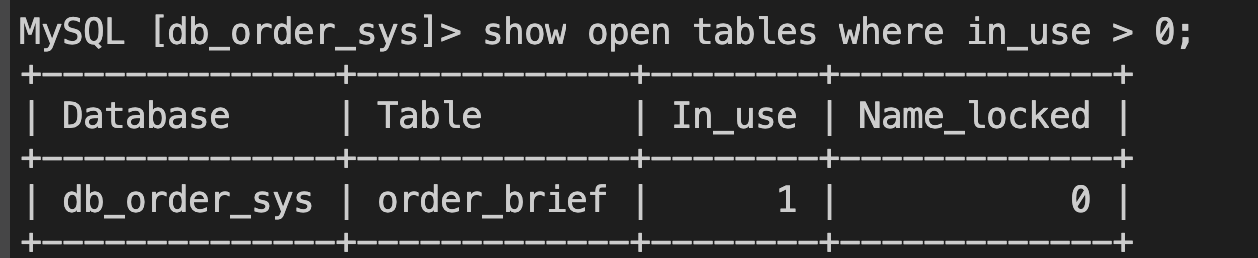
按照官方文档:
https://dev.mysql.com/doc/refman/5.7/en/show-open-tables.html
所述:

In_use大于0,表示当前表已经被锁了,但是innoDB,有MVCC并发度机制,对于select而言是读的快照,通过对比事务id的先后,保证读取的时候不会出现冲突和锁表,这个结论和官方的结论有冲突,而我们平常来说,读表是不加锁的。
但是innoDB的锁(https://dev.mysql.com/doc/refman/5.7/en/innodb-introduction.html)有一个意向读锁(IS)和读锁(S),而且也有文档说,如果select的where子句的字段是有索引的,那么加的是行锁,否则会降级成表锁。
mysql创建索引
https://blog.csdn.net/nangeali/article/details/73384780
https://blog.csdn.net/m0_43448868/article/details/102312327?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.highlightwordscore&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.highlightwordscore
mysql的collate
collate只会影响排序的顺序已经搜索的时候会不会匹配的上这条记录,并不影响数据存入数据库的时候的编码,编码是由charset指定的。
https://juejin.cn/post/6844903726499512334
不同的collation有区别,性能、大小写敏感上都有区别,这些都会导致搜索和排序的不同。上面的url是utf8mb4的collate对比,建议使用utf8mb4_unicode_ci
innodb的锁介绍
https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html
mysql的写操作存在锁表可能性
网上说的一次批量删除5000条以上可能会锁表,所以批量写的操作尽量控制量级,避免影响别的业务
mysqldump: Got error: 2002: "Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)" when trying to connect
https://stackoverflow.com/questions/15318875/mysqldump-cannot-connect-using-socket
https://blog.csdn.net/hjf161105/article/details/78850658
查看mysql磁盘占用
select
table_schema, sum((data_length+index_length)/1024/1024) M
from
information_schema.tables
where
table_schema is not null
group by
table_schema ;
或者
select TABLE_SCHEMA, concat(truncate(sum(data_length)/1024/1024,2),' MB') as data_size, concat(truncate(sum(index_length)/1024/1024,2),'MB') as index_size from information_schema.tables group by TABLE_SCHEMA order by data_size desc;
两者是等价的
使用select的结果进行update
UPDATE
`table1` AS `dest`,
(
SELECT
*
FROM
`table2`
WHERE
`id` = x
) AS `src`
SET
`dest`.`col1` = `src`.`col1`
WHERE
`dest`.`id` = x
;
查看mysql binlog日志
使用mysqlbinlog程序
mysqlbinlog -vv mysql-bin.000001
/usr/local/mysql/bin/mysqlbinlog --start-datetime=
"2013-03-01 00:00:00"
--stop-datetime=
"2014-03-21 23:59:59"
/usr/local/mysql/
var
/mysql-bin.000007 -r test2.sql
查看数据库的占用情况
USE information_schema;
SELECT TABLE_SCHEMA, SUM(DATA_LENGTH)/1024 FROM TABLES GROUP BY TABLE_SCHEMA; (kb展示,如果要MB、GB,则再除以1024,1024/1024)
mysql插入datetime类型的字段
insert into tweets values('2017-03-02 15:22:22');
insert into tweets values('2017-03-02 16:34');
//末尾秒,分,时,可以依次省略,但日,月,年不可以省略
insert into A select * from B的锁情况分析
https://www.cnblogs.com/zhoujinyi/archive/2013/04/28/3049382.html
通过主键排序或则不加排序字段的导入操作"insert into tb select * from tbx",是会锁tbx表,但他的锁是逐步地锁定已经扫描过的记录。
通过非主键排序的导入操作"insert into tb select * from tbx",是会锁tbx表,但他的锁是一开始就会锁定整张表。
https://www.modb.pro/db/33967
这里有查看锁状态的方式,如果select的子句走了全表扫描,则会锁全表,如果有索引才不会;(这里的锁全表是指,全表扫描,扫到一行记录就锁一行;而如果是有索引的,则只会锁住符合条件的索引所在的行,影响范围小)
https://blog.csdn.net/piaoranyuji/article/details/116303552
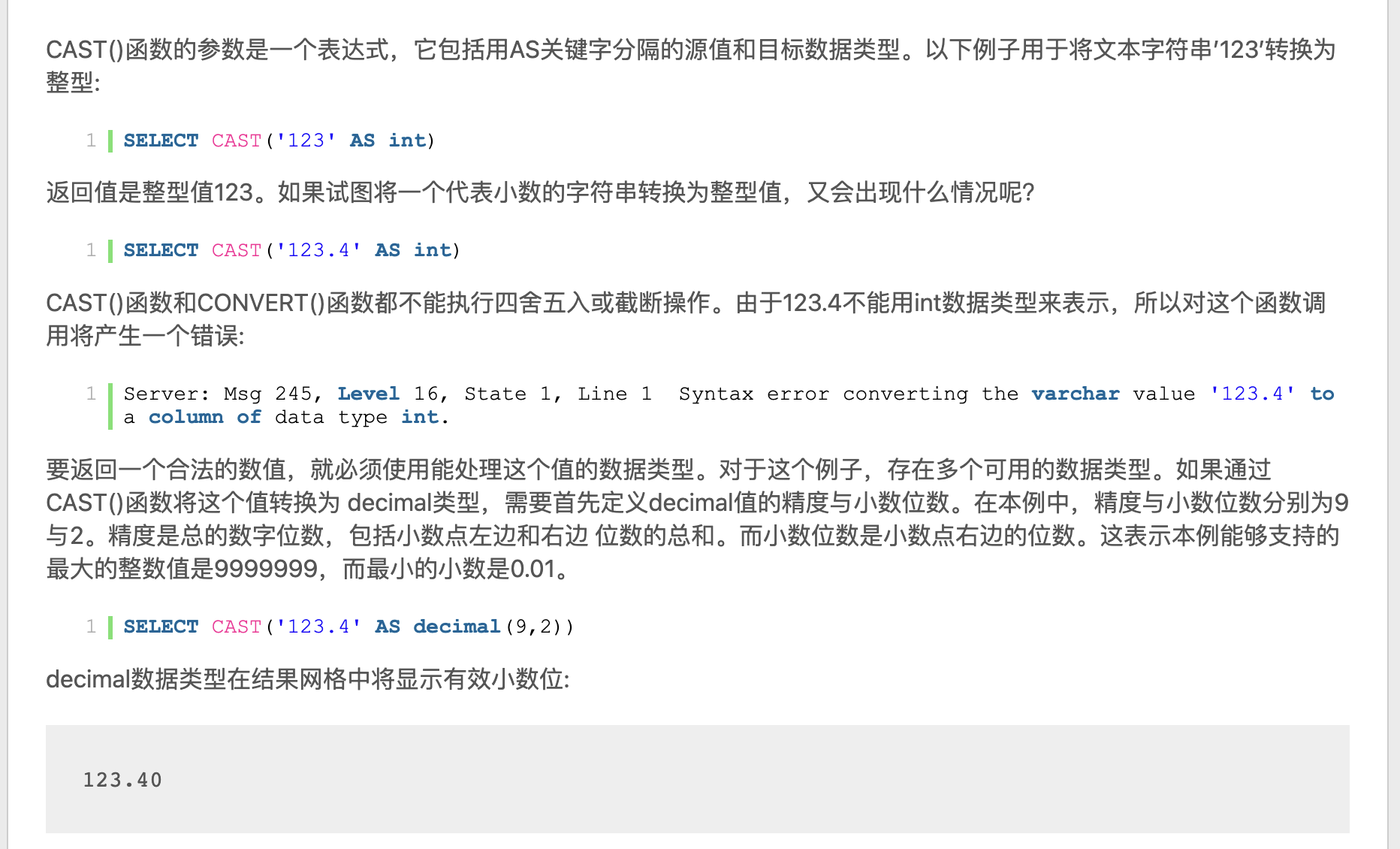
字符串转数值类型
https://justcode.ikeepstudying.com/2016/08/mysql-%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E%8B%E8%BD%AC%E6%8D%A2%E5%87%BD%E6%95%B0convertconcatcast/
mysql增加表索引
添加单个索引
alter table your_table add index index_name(column_name);
添加组合索引
alter table your_table add index index_name(column1,column2,column3);
需要注意,增加索引会导致锁表(虽然mysql5.7以后有online DDL,但是也会在起始和结束阶段进行锁表,实测100w的数据增加单个整数字段索引需要1.5s左右),因此如果线上大量数据的数据库,在增加索引时应找一个业务低峰期进行操作;因此最好在设计初期就确定好索引;
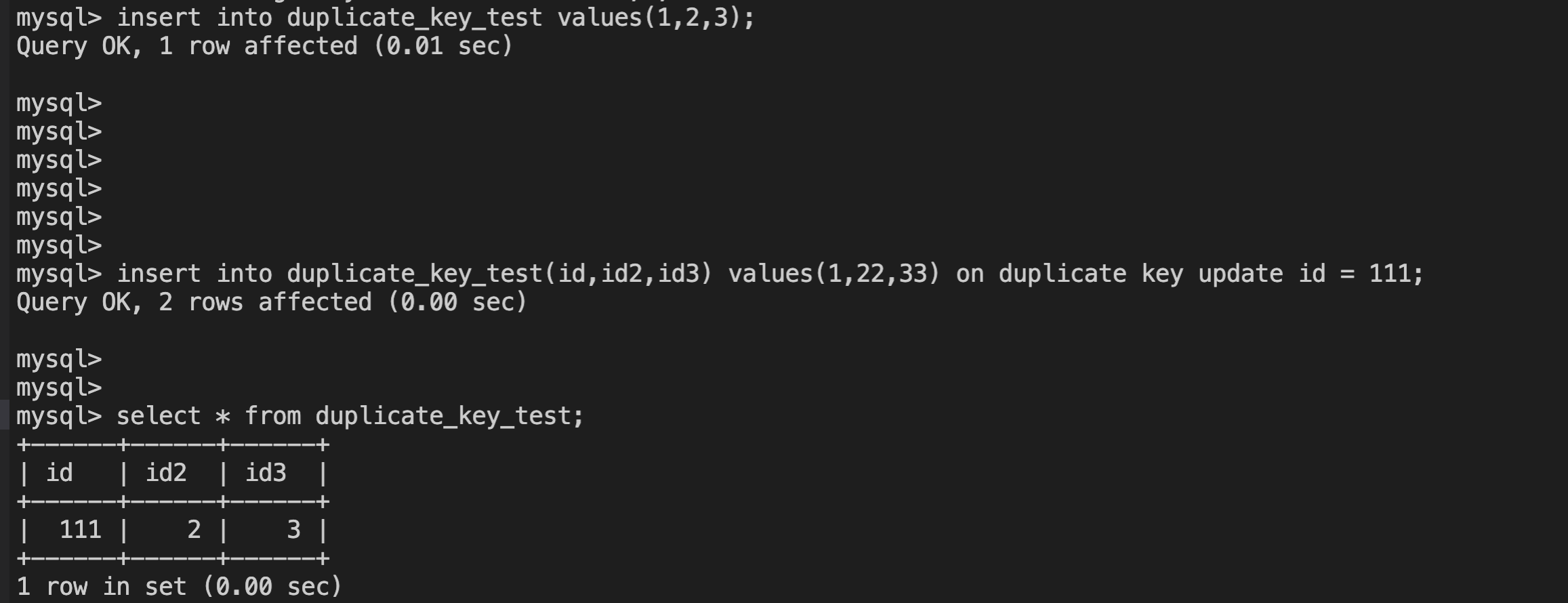
insert ... on duplicate key update statement
https://dev.mysql.com/doc/refman/8.0/en/insert-on-duplicate.html
这个sql是为了解决在插入数据时,出现key冲突的问题;
他会去update冲突的当前表里已有的那行数据,而不是update插入的数据,这点尤其需要注意;
官方的一个case,假设字段a是unique的,下面这两行有相似的作用:
INSERT INTO t1 (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1;
UPDATE t1 SET c=c+1 WHERE a=1;
相当于说,这个语法是当发现冲突的时候,就不是做真正的insert,而是对冲突的数据,做了一次update操作,并没有insert;
这里要注意affected rows,下图中,数据实际上只有一行的修改,但是affected row=2;
(With ON DUPLICATE KEY UPDATE, the affected-rows value per row is 1 if the row is inserted as a new row, 2 if an existing row is updated, and 0 if an existing row is set to its current values.)

如果b也是unique列,那么这个insert语句和下面的sql是等价的
UPDATE t1 SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
如果上面的where条件满足了好几行数据,只有一行会被更新,所以要避免这种会出现多行的情况,不然使用上的insert语句就会带来预料之外的更新效果
concat 和group_concat
concat是平常会使用到的拼接,将同一行数据多个字段的值拼接成新的字符串,并且还可以指定拼接的连接符;
https://www.w3resource.com/mysql/string-functions/mysql-concat-function.php
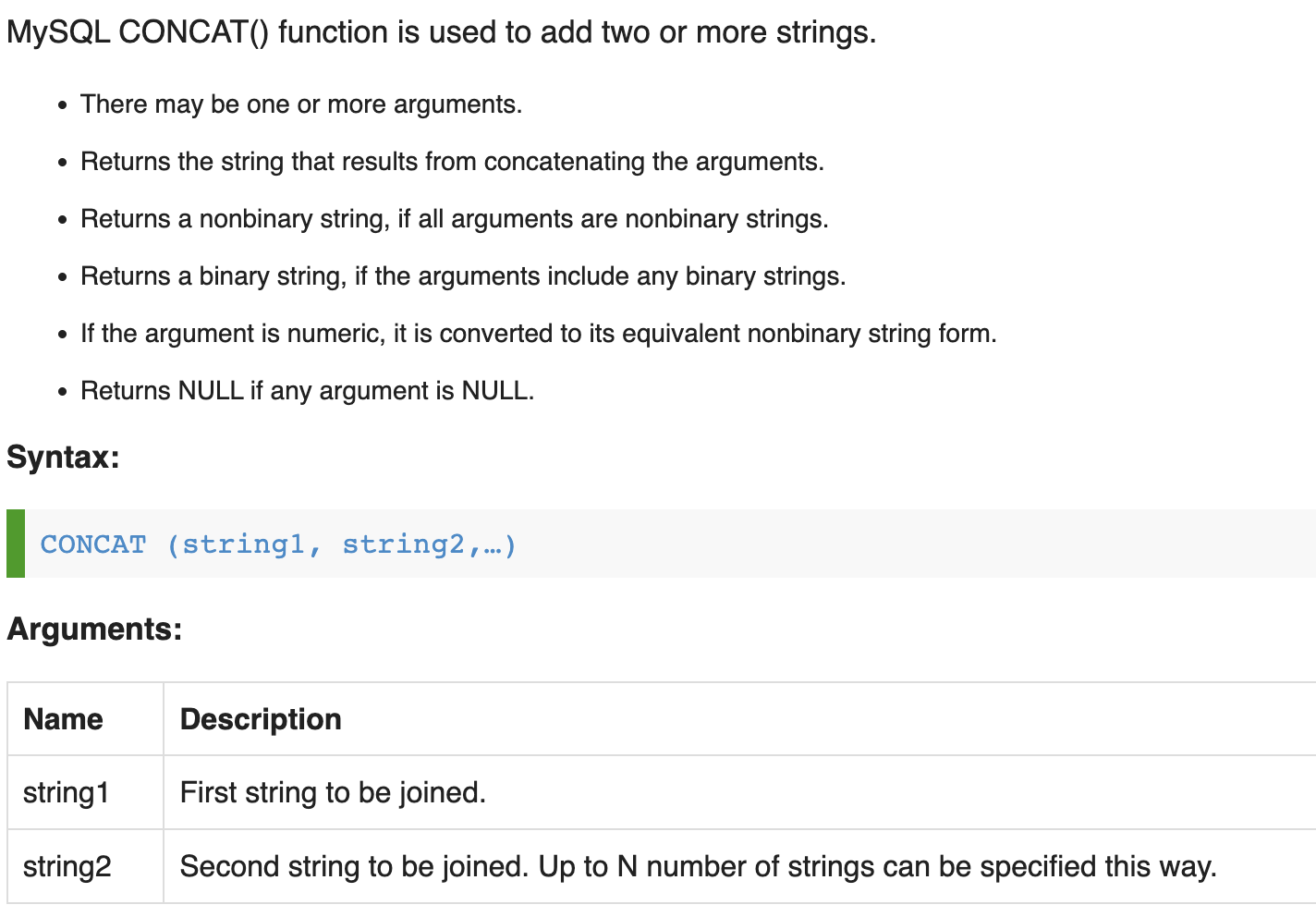
concat默认是直接连接几个字段的值,如果想要指定连接符,需要使用concat_ws
ws含义为with separator的意思,其余特性和concat一致;
concat_ws(separator, str1, str2, ...)
上面都是同一行的数据多字段拼接(横向拼接),如果想要多行的某个字段拼接(纵向拼接),则需要使用group_concat
https://www.w3resource.com/mysql/aggregate-functions-and-grouping/aggregate-functions-and-grouping-group_concat.php
https://www.yiibai.com/mysql/group_concat.html
group_concat就是从分组的结果中,对指定的字段列进行纵向数据合并;如果sql不指定group by,则整张表当成一个分组来进行concat;默认的连接符为逗号;


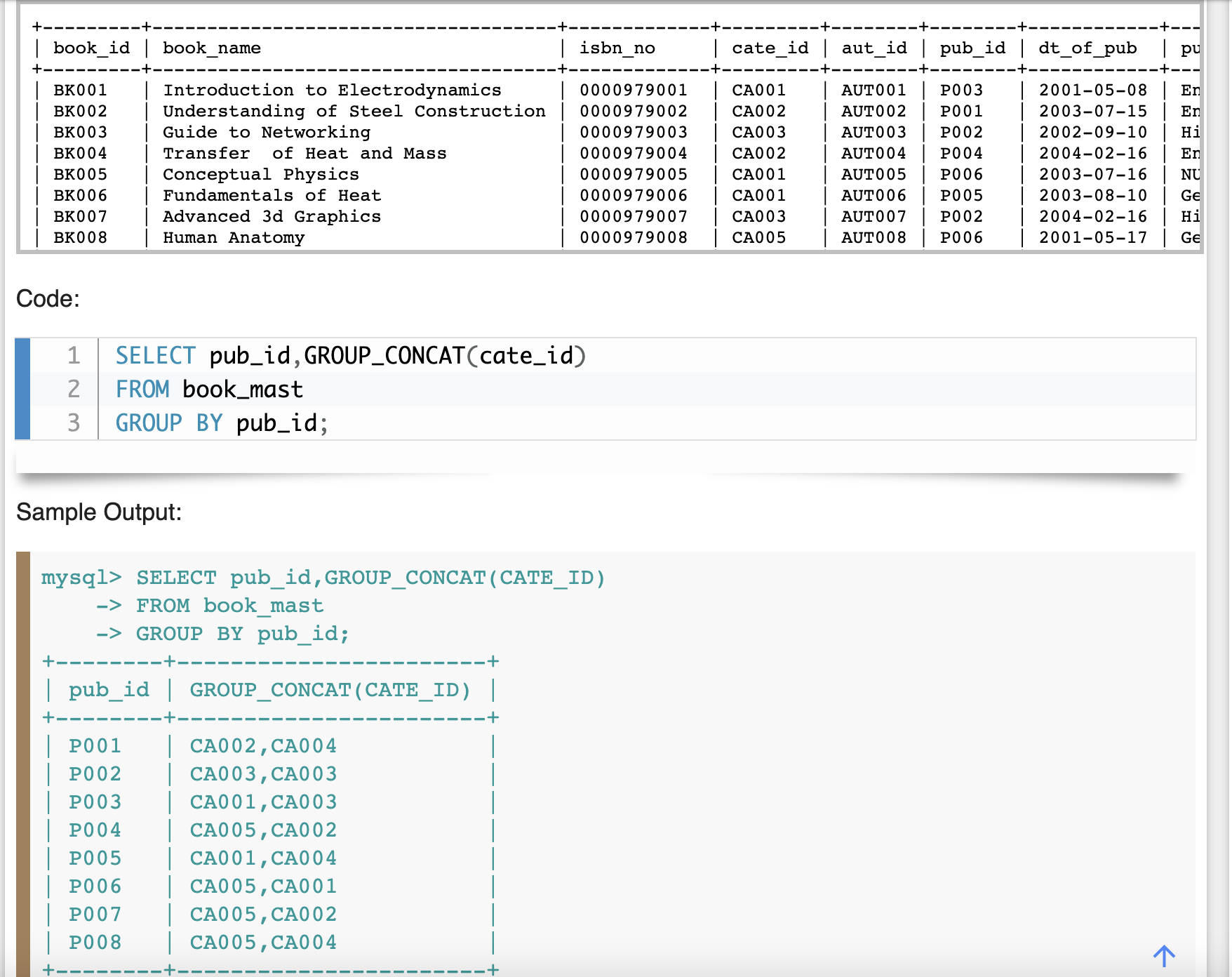
group_concat的结果字符串有默认长度1024的字符,如果超过这个,会被截断;
可以通过设置:
show variables like 'group_concat_max_len';
set session group_concat_max_len = -1
-1为最大值或根据实际需求设置长度;如果想要设置全局的,需要修改配置文件,group_concat_max_len = -1
mysql aborted 告警日志
https://blog.csdn.net/u010584271/article/details/81806226
aborted日志多数是因为空闲等待时间超过了mysql的设置,超过这个设置后,就会aborted;
但是也有因为密码输入错误引起的aborted,具体的各种类型,参考上面的链接;
mysql各字符集下汉字和字母占字节数
varchar(N), 这里的N是指字符数(character),并不是字节数(byte).占用的字节数与编码有关
在mysql 5.7下测试得出如下结论
latin1:
1character=1byte, 1汉字=3character,
也就是说一个字段定义成 varchar(300),则它可以存储100个汉字或者300个字母。
这一点要注意,尤其是当字段内容是字母和汉字组成时,尽量假设字段内容都是由汉字组成,据此来设置字段长度
utf8:
1character=3bytes, 1汉字=1character
也就是说一个字段定义成 varchar(200),则它可以存储200个汉字或者200个字母。
gbk:
1character=2bytes,1汉字=1character
也就是说一个字段定义成 varchar(200),则它可以存储200个汉字或者200个字母。
mysql的一些参数配置
max_execution_time
这个变量的设置表示一条sql的执行最大时长,如果在连接正常,但是sql执行时间过长的情况下,只要超过了这个时间,就会被mysql给kill掉;
https://blog.51cto.com/u_8865295/2938393
如果这个参数给为0,表示不做任何限制
skip_name_resolve参数
mysql可以将客户端的ip和客户端的主机名进行反向dns解析,这样就可以对主机名进行授权,而不是只能对ip进行授权访问;
当客户端连接过来后,mysql会对这个ip进行查询其主机名,首先会在/etc/hosts下查找,如果找不到就会使用mysql的dns解析,就进行反向解析,如果没有设置,就会直接错误返回;
所以如果有反向解析这个环节,就会出现在连接的时候反向解析耗时的情况,如果都找不到会报错,或者一直到超时,增加连接耗时;
并且解析之后,会把ip和主机名的映射关系存入到host_cache表中,如果开启了解析功能,查看这个表就能看到当前的缓存,并且后续同个主机的访问不再需要进行反向解析,从host_cache表读出即可。
https://dev.mysql.com/doc/refman/5.6/en/host-cache.html
skip_name_resolve参数的作用就是跳过这个解析过程,提高连接速度,但是这样之后就只能对ip授权访问了。

中止正在执行的sql语句
show processlist;
show full processlist;
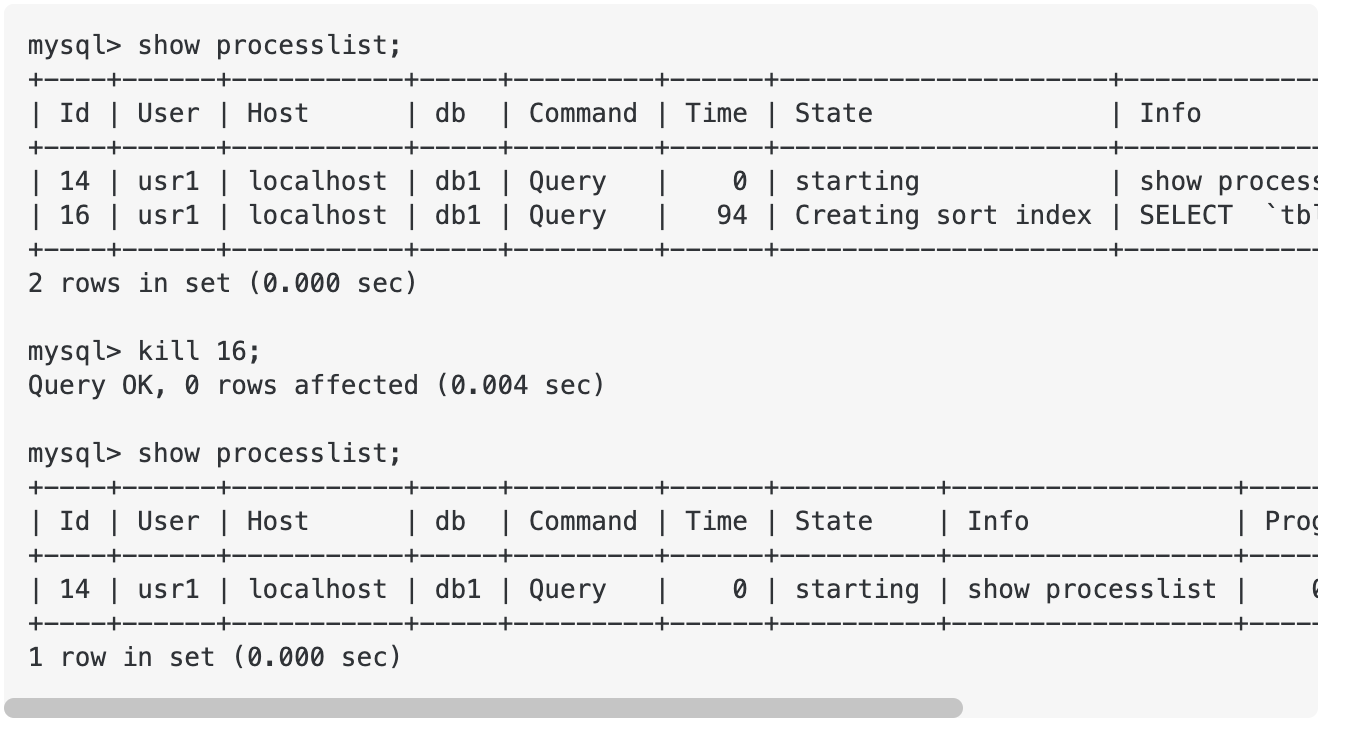
可以使用kill Id 或者kill query Id来实现这个效果,但是kill会把连接也给弄中断,使用kill query则只中止这一次的sql执行。
添加索引
https://blog.csdn.net/zhangjq520/article/details/73289459
alter table my_table add index index_name(column_list); 普通索引
alter table my_table add unique index_name(column_list); 唯一索引
alter table my_table add fulltext index_name(column_list); 全文索引
alter table my_table add primary index_name(column_list); 主键索引
example:
alter table my_table add index my_index_name(name);
添加/修改字段
alter table my_table add column new_col_name type default '' comment 'test';
alter table my_table modify column my_old_col type default '' comment 'change col';
aborted log
https://severalnines.com/database-blog/common-mysql-error-got-error-reading-communication-packet
如果mysql错误日志出现了很多aborted log,可以参考上面的文章进行处理,大多数是跟mysql的配置超时时间有关系;
https://dev.mysql.com/doc/refman/5.6/en/server-status-variables.html#statvar_Connection_errors_xxx
同时官网的错误变量的含义解释也可以帮助定位;
可参考的解决方法:
1、在MySQL内部,MySQL内部处于休眠了几百秒的状态的连接中很大比例是应用程序在完成工作后没有关闭连接造成的,而是依靠wait_tiemout系统变量来关闭连接。我强烈建议修改应用程序逻辑,在操作结束后正确关闭连接
2、检查以确保max_allowed_packet足够大,你的客户端不会收到"packet too large"的消息。这种情况下的连接断开属于由于没有正确关闭连接
3、另外一种可能是TIME_WAIT。我曾经多次从netstat注意到TIME_WAIT提示,所以我建议在应用端确认正确关闭连接
4、确保事务提交(begin和commit)都正确提交以保证一旦应用程序完成以后留下的连接是处于干净的状态
5、你应该确保客户端程序不会断开连接。例如,如果设置了max_execution_time为5秒,增加connect_timeout并不会起到作用,因为会kill脚本。其他程序语言和环境也有类似的安全选项
6、连接延迟的另外一个原因是DNS问题。检查参数skip-name-resolve是否打开,以及是否根据主机的IP地址而不是主机名对主机进行身份验证
7、发现你的应用程序故障的一种办法是添加一些日志到你的代码中来保存包含连接ID的应用程序行为。有了它,你能够将连接数字与错误行数对应起来了。打开审计日志插件,日志记录了连接和查询操作,一旦触发到了连接断开的错误,你都应该检查Percona审计日志。你可以通过检查审计日志找出哪个查询是根本原因。如果由于某些原因你不能使用审计日志,你可以考虑使用MySQL的常规日志-然而对于高负载的服务器来说这样是有风险的。再不济,你可以打开常规日志几分钟。打开常规日志会给服务器增加巨大负担,并且经常会发生错误,因此你应该在日志增长太大之前就收集完数据。我建议打开常规日志并使用tail -f,然后当你在日志中看到下一个警告时关闭。一旦从断开的连接中找到查询,请确定查询的应用程序问题的哪一部分,并将查询与应用程序的某些部分关联起来。
8、尝试增加MySQL的net_read_timeout和net_write_timeout的参数值然后观察是否减少错误数。net_read_timeout一般很少出问题,除非你的网络真的很糟糕。但是,尝试调整这些值,因为在大多数情况下,生成一个查询并将其作为一个包发送到服务器,而应用程序不能在将部分接收到的查询留给服务器的同时去做其他事情
查询表字段数
SELECT count(1) from information_schema.COLUMNS WHERE table_schema='db_name' and table_name='table_name';
查看表字段数 或者直接desc table \G